Performance¶
The EMBERS pipline comes with a series of command-line tools for batch processing data. These tools are parallelized to process large volumes of data using
all available CPU cores. Exampes of these tools and their usage are available on the EMBERS by Exampe Page. The most resource hungry
section of the pipline is the align_batch tool, which temporally aligns pairs of RF data files, interpolates them down to lower frequencies and smooths
noisy data using a SavGol Filter. When running EMBERS of a laptop, it
may be advisible to use the --max_cores option to limit the number of cores availible to this tool. Below, we analyse the performance
of the align_batch tool.
Parallel Performance Test¶
To get a handle of the parallel performance of align_batch, the --max_cores option was used to time the execution of the tool with between 1 and 4
CPU cores. The GNU time tool was used to gauge performance.
The terminal outputs of a test on a laptop are shown below:
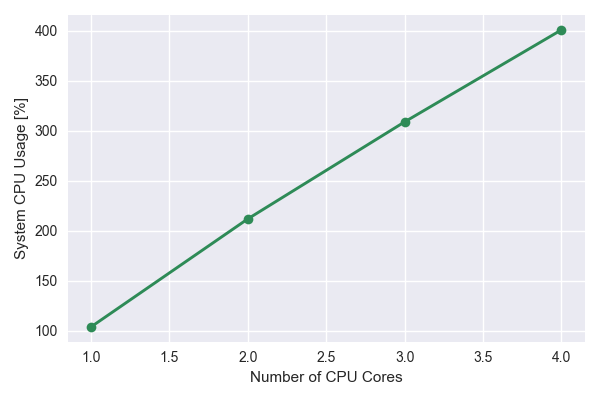
The system cpu usage vs number of cpu cores increases linearly as expected
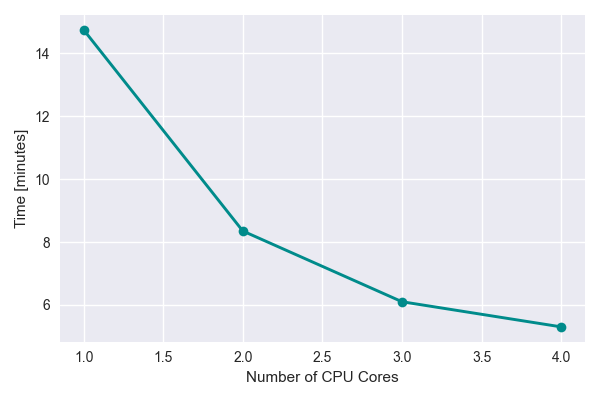
The time vs number of CPU cores seems to fall off at higher number of cores. This could partially be due to limited resources available on the laptop.
Single Core Performance¶
align_batch was re-run with --max_core=1 option set to limit the tool to a single CPU core. The number of files were varied to understand the
how the performance scaled with increasing number of files. The results indicate a linear increase in processing time with increasing data files.
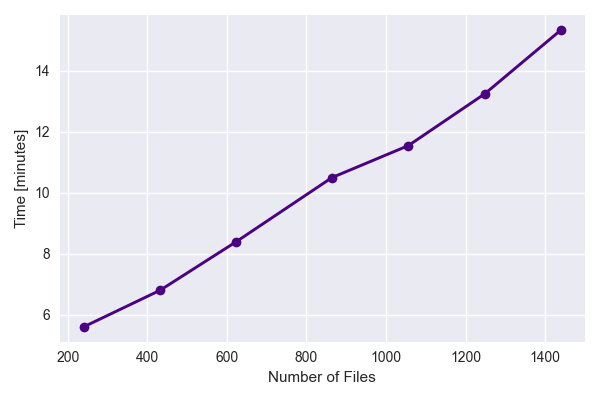
Finally, we test the perfomance on a single tile while varying the amount of data per file. This is done by only analysing various fractions of the data array in a single file and timing the perfomance.
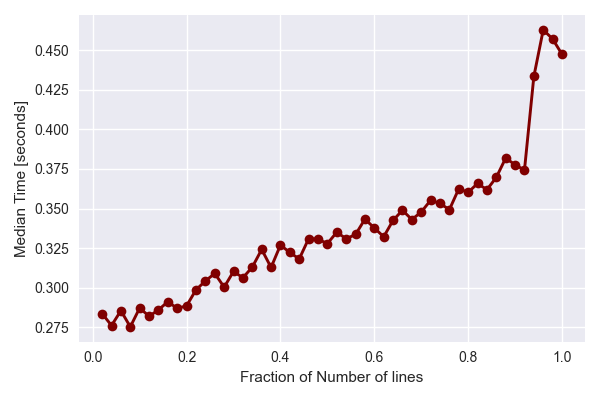
The results show that while the processing time increases linearly with the amount of data per file, there is a significant overhead attributed to reading the data from disk. Each file typically takes ~200 ms to read in, before it can be analysed. This may result from the decoding process from binary to floats.
For a more details discussion on the perfomance aspects of the tool, check out the comments at the bottom of the following Github Issue.